Data Lake cần data Catalog. Chúng ta đang sống trong thời đại bùng nổ và đổi mới dữ liệu. Trong khi các tổ chức lớn đang tập trung vào các giải pháp lưu trữ dữ liệu tại chỗ và phát triển trung tâm dữ liệu data lake, họ cũng đang thử nghiệm các giải pháp đám mây. Một số, trong nỗ lực hợp lý hóa hoạt động và tập trung vào hoạt động kinh doanh cốt lõi của mình, đã chuyển toàn bộ cơ sở hạ tầng CNTT của họ ra khỏi cơ sở.
Table of Contents
Siêu dữ liệu bị mất hoặc không có sẵn
Sau khi dữ liệu được tải từ Phòng Kế toán vào data lake, tất cả các kiến thức nội bộ về dữ liệu đó đều bị thiếu (vì ngay từ đầu nó chưa bao giờ có ở đó) hoặc bị mất , ví dụ:
- Chất lượng của dữ liệu này là gì?
- Dữ liệu này được sử dụng ở đâu?
- Ai là chủ sở hữu của dữ liệu?
- Bên trong dữ liệu này có gì?
- Nguồn của dữ liệu này là gì?
- Dữ liệu này được cập nhật thường xuyên như thế nào?
Giải pháp: Quản lý siêu dữ liệu
Khi bạn thêm nguồn dữ liệu (như cơ sở dữ liệu của Phòng Kế toán), cần phải thêm tất cả siêu dữ liệu quan trọng về nguồn đó: chủ sở hữu, thuật ngữ và danh mục kinh doanh được liên kết với nguồn, nguồn gốc của nguồn và bất kỳ siêu dữ liệu nào khác quan trọng đối với tổ chức của bạn. Do đó, các nhà khoa học dữ liệu có thể tìm kiếm và lọc theo siêu dữ liệu này và tìm thấy chính xác dữ liệu họ đang tìm kiếm .
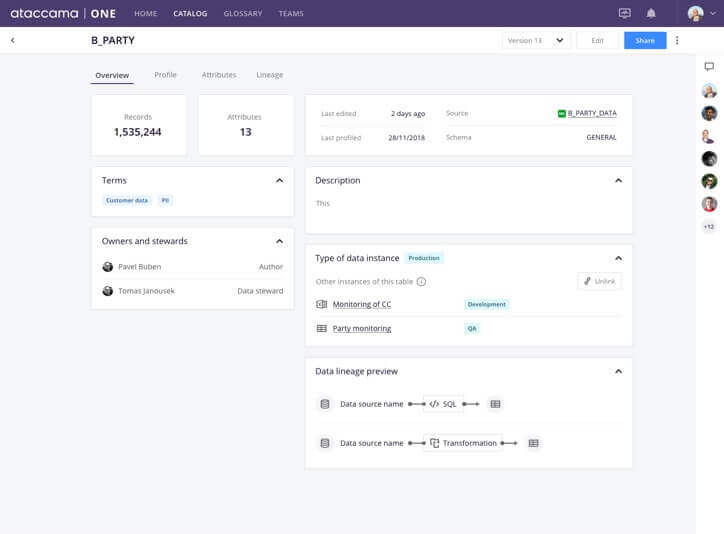
Dữ liệu nhạy cảm có thể xâm nhập vào data lake
Vì các cột mới có thể được thêm vào bảng cơ sở dữ liệu của Phòng Kế toán nên dữ liệu mới—bao gồm cả dữ liệu nhạy cảm—có thể được tải vào data lakemà không ai biết. Vấn đề này đặc biệt liên quan đến việc truyền dữ liệu, trong đó không có giao diện nghiêm ngặt nào được xác định cho dữ liệu đến.
Giải pháp: Tự động lập hồ sơ, gắn thẻ và chính sách dữ liệu trong danh mục dữ liệu
Khi dữ liệu mới được đưa vào danh mục, nó sẽ tự động được lập hồ sơ và gắn thẻ để truy xuất ý nghĩa ngữ nghĩa của nó. Với các quyền và chính sách dữ liệu được áp dụng, khi phát hiện một loại dữ liệu cụ thể (ví dụ: một cột có dữ liệu về tiền lương), dữ liệu đó sẽ bị che, băm hoặc ẩn đối với phần lớn người dùng. Chỉ những người dùng thuộc nhóm quản lý mới có thể nhìn thấy dữ liệu này.
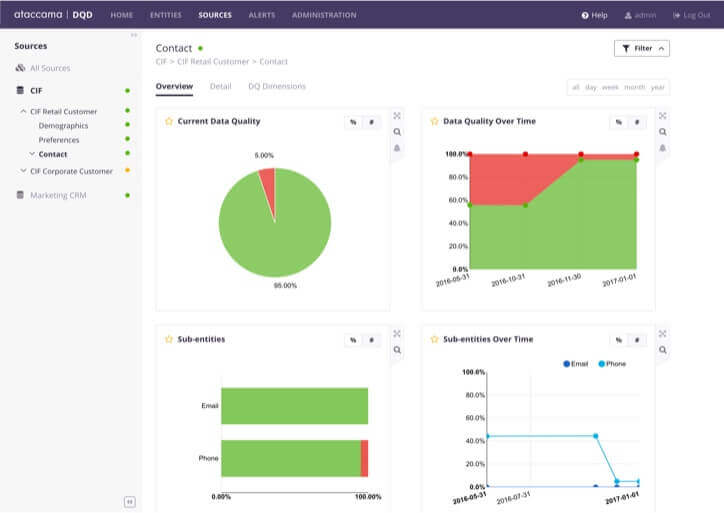
Chất lượng dữ liệu không xác định
Khi người dùng trực tiếp sử dụng tập dữ liệu từ hồ, họ không biết chất lượng của nó. Hoặc họ phải lập hồ sơ dữ liệu theo yêu cầu trong một công cụ độc lập (việc này chỉ mất thời gian) hoặc họ sử dụng dữ liệu không đáng tin cậy trong phân tích của mình.
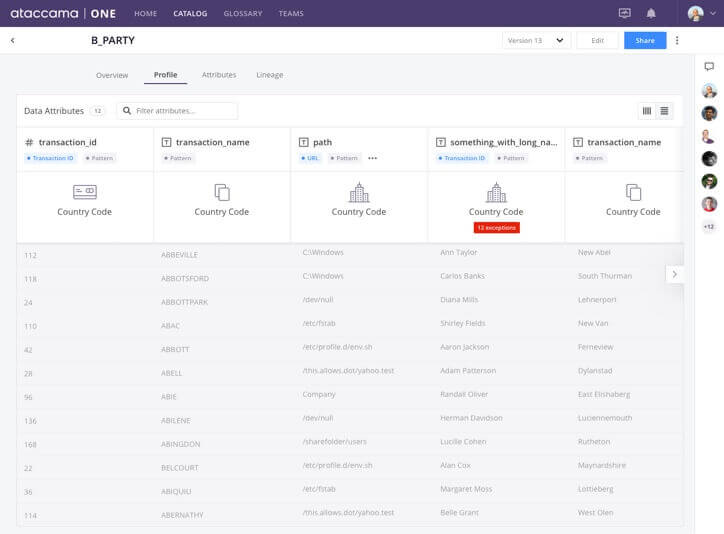
Giải pháp: Tính năng lập hồ sơ, chất lượng dữ liệu và chuẩn bị dữ liệu
Khi người dùng tìm thấy một tập dữ liệu trong danh mục dữ liệu, họ sẽ biết chính xác chất lượng của nội dung đó. Nhờ cấu hình dữ liệu , họ có thể thấy các ô trùng lặp, trống, không chuẩn trong bất kỳ cột nào và đánh giá xem có nên sử dụng tập dữ liệu đó hay không . Nếu danh mục dữ liệu có khả năng chuẩn bị dữ liệu, người dùng có thể ngay lập tức làm sạch và sắp xếp lại tập dữ liệu và làm cho nó có thể sử dụng được cho việc phân tích của họ.
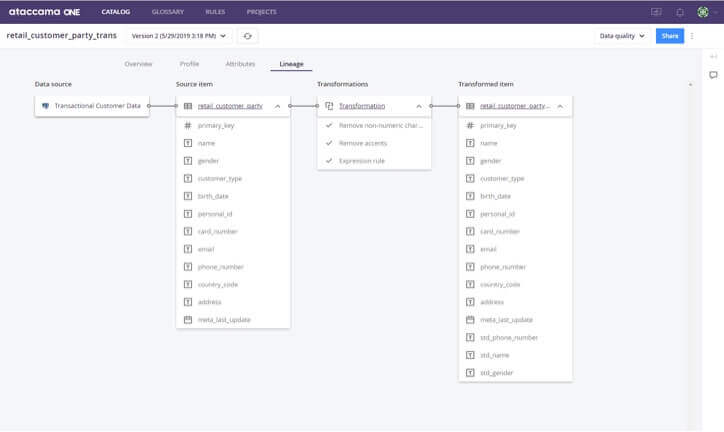
Không hiểu rõ về nguồn gốc dữ liệu và mối quan hệ với các tài sản khác
Rất nhiều biến đổi diễn ra bên trong data lake. Các nhà khoa học dữ liệu chuyển đổi dữ liệu và lưu trữ các bảng mới trong data lake. Khi dữ liệu được xuất sang kho dữ liệu, nó cũng được chuyển đổi ở đó. Khi người dùng tìm thấy nội dung trong danh mục dữ liệu, họ muốn hiểu nội dung này nằm ở đâu trong chu trình chuyển đổi đó.
Đối với người dùng doanh nghiệp, điều quan trọng là phải hiểu dữ liệu nào được đưa vào tạo báo cáo. Đối với các kỹ sư dữ liệu và CNTT, điều quan trọng là phải hiểu những báo cáo nào sẽ bị ảnh hưởng nếu họ thực hiện các thay đổi đối với bảng.
Đối với các nhà khoa học dữ liệu, điều quan trọng là sử dụng tập dữ liệu phù hợp nhất trong phân tích của họ, vì vậy họ cần càng nhiều thông tin càng tốt về nguồn gốc và mục đích sử dụng tiếp theo của nó.
Giải pháp: Dòng dữ liệu và khám phá mối quan hệ tự động
Dòng dữ liệu là một chủ đề nóng trong ngành quản lý dữ liệu và mỗi nhà cung cấp có cách tiếp cận khác nhau để cung cấp tính năng này. Một số phương pháp dành riêng cho nền tảng: phân tích nhật ký SQL và công việc Spark hoặc tích hợp với các công cụ ETL thông qua API REST. Một cách nữa là cho phép người dùng xây dựng dòng theo cách thủ công.
Những phương pháp này thực hiện phức tạp và không bao giờ có thể xây dựng dòng dõi cho 100% trường hợp. SQL có nhiều loại và một số trong đó không thể phân tích được. Công việc Spark có thể bị xóa ngay cả khi bảng mà nó tạo ra vẫn tồn tại. Các công cụ ETL có các cách tiếp cận khác nhau để lưu trữ thông tin về các phép biến đổi của chúng, những thông tin này khó hoặc không thể truy cập được.
Kết luận
Triển khai data lake là một công việc to lớn, không chỉ từ quan điểm công nghệ mà còn từ quan điểm quản trị dữ liệu . data lake là một giải pháp tuyệt vời để cung cấp dữ liệu cho những người cần nó, nhưng chúng vốn có một số thiếu sót và gây ra một số vấn đề khiến chúng khó sử dụng và an toàn hơn mức có thể.
Danh mục dữ liệu giải quyết những vấn đề này thông qua các quy trình tự động và thủ công nhằm làm phong phú các tập dữ liệu với nhiều loại siêu dữ liệu và tạo thành các tài sản dữ liệu hữu ích, được bảo vệ và kiểm toán từ chúng
Cảm ơn bạn đã đọc bài viết. Chúng tôi tự hào cung cấp các dịch vụ đa dạng trong lĩnh vực CNTT, bao gồm:
Triển khai kho dữ liệu DWH: Giải pháp lưu trữ dữ liệu, giúp doanh nghiệp tối ưu hóa việc quản lý và phân tích dữ liệu lớn.
Dịch vụ phát triển phần mềm: Tạo ra các ứng dụng và giải pháp phần mềm tùy chỉnh để đáp ứng nhu cầu cụ thể của bạn.
Dịch vụ IT Outsourcing: Đội ngũ chuyên gia dữ liệu giàu kinh nghiệm, sẵn sàng gia nhập và thúc đẩy dự án của bạn.
Dịch vụ xây dựng báo cáo BI: Chuyển đổi dữ liệu thô thành thông tin chiến lược giúp ra quyết định chính xác hơn.
Đào tạo về dữ liệu: Các khóa học chất lượng cao, thiết kế dành riêng cho doanh nghiệp, giúp nâng cao kỹ năng và kiến thức về dữ liệu của đội ngũ của bạn.

