
Table of Contents
Mở đầu
Tối ưu hóa câu lệnh SQL rất quan trọng trong những phần mềm liên quan nhiều đến nghiệp vụ như ngân hàng, quản lý buôn bán sản phẩm của các tập đoàn, công ty lớn… thì số lượng records trong DB rất lớn. Việc join nhiều table với hàng trăm, chục nghìn bản ghi là thường xuyên xảy ra. Một trong những phương pháp cần thiết để tốc độ của hệ thống được đảm bảo là phải tối ưu hóa từng dòng lệnh SQL.
Index
Chỉ mục (Index) là bảng tra cứu đặc biệt mà Database Search Engine có thể sử dụng để tăng nhanh thời gian và hiệu suất thu thập dữ liệu. Hiểu đơn giản, một chỉ mục là một con trỏ tới dữ liệu trong một bảng. Một chỉ mục trong một Database là tương tự như một chỉ mục trong Mục lục của cuốn sách. Index giúp tăng tốc các truy vấn SELECT và các mệnh đề WHERE, nhưng nó làm chậm việc dữ liệu nhập vào, với các lệnh UPDATE và INSERT. Các chỉ mục có thể được tạo hoặc xóa mà không ảnh hưởng tới dữ liệu. Việc sử dụng Index sẽ phù hợp với những DB có lượng dữ liệu lớn và ít có thay đổi như thông tin khách hàng của ngân hàng. Tạo Index như sau :
CREATE INDEX index_name ON table_name;
Xóa Index
DROP INDEX index_name;
Các nguyên nhân gây chậm truy vấn SQL
- Không/thiếu sử dụng các lợi ích của Indexes.
- Trả về các dữ liệu không cần thiết.
- Locks or deadlocks bị cấm.
- Các câu truy vấn được viết nghèo nàn.
- Không/thiếu tận dụng được I/O striping.
- Thiếu bộ nhớ.
Các phương pháp cải tiến
Thu hẹp giá trị trả về
việc thu hẹp giới hạn của giá trị trả về sẽ tiết kiệm bộ nhớ, I/O striping, dung lượng khi truyền từ server về client.
SELECT * FROM table_1 LEFTJOIN table_2 WHERE table_1.id = table_2.gid;
sử dụng select * sẽ khiến SQL quét toàn bộ table,trả về dữ liệu trùng lặp tiêu tốn I/O.Truy vấn dưới đây cùng mục đích nhưng nhanh hơn.
SELECT table_1.id,table_2.username,table_2.lucky FROM table_1 LEFTJOIN table_2 WHERE table_1.id = table_2.gid;
không hạn chế Index
- toán tử phủ định : Index không thể thực hiện với toán tử phủ định do đó các toán tử phía dưới sẽ làm chậm câu lệnh hãy hạn chế sử dụng.
"IS NULL", "!=", "!>", "!<", "NOT", "NOT EXISTS", "NOT IN", "NOT LIKE",
- toán tử so sánh 2 lần
SELECT userid, username FROM user WHERE user_amount <=3000
câu lệnh này sẽ khiến SQL so sánh 2 lần : user_amount< 3000 OR user_amount=3000 do đó làm chậm truy vấn.Hãy dùng câu lệnh dưới đây cho tình huống tương tự.
SELECT userid, username FROM user WHERE user_amount < 3001
Sử dụng Like không hợp lý sẽ làm chậm truy vấn:
SELECT lname, fname, address FROM Customers WHERE fname LIKE ‘%V%’
câu lệnh này so khớp phần đầu của %V vì thế không thể dùng index mặc dù điều kiện tìm kiếm rõ hơn nhưng sẽ chậm hơn câu lệnh dưới đây.
SELECT lname, fname, address FROM Customers WHERE fname LIKE ‘V%’
- hạn chế sử dụng function lên column
SELECT member_number, first_name, last_name
FROM members
WHERE DATEDIFF(yy,datofbirth,GETDATE()) > 21
sau khi tính toán bởi hàm DATEDIFF thì SQL không thể dùng Index cho column datofbirth được nữa.sử dụng câu truy vấn như dưới đây sẽ nhanh hơn.
SELECT member_number, first_name, last_name
FROM members
WHERE dateofbirth < DATEADD(yy,-21,GETDATE())
Không để SQL thực hiện thao tác thừa
- UNION, UNION ALL
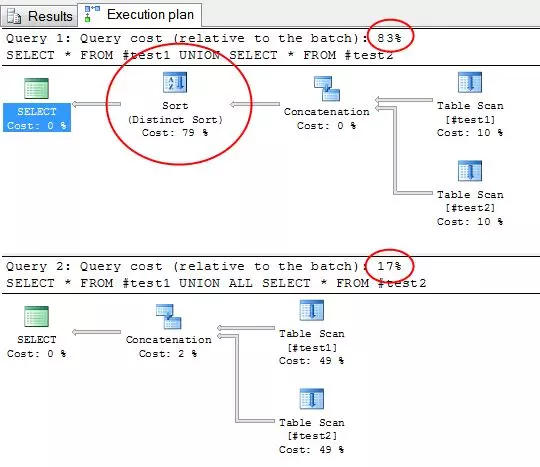 mặc dù cả 2 câu truy vấn đều quét table như nhau nhưng ở câu truy vấn 1 tiêu tốn phần lớn thời gian cho thao tác 「Distinct sort」để loại bỏ những bản ghi trùng nhau (mặc dù không hề có những records như vậy). đây là 1 ví dụ khác :
mặc dù cả 2 câu truy vấn đều quét table như nhau nhưng ở câu truy vấn 1 tiêu tốn phần lớn thời gian cho thao tác 「Distinct sort」để loại bỏ những bản ghi trùng nhau (mặc dù không hề có những records như vậy). đây là 1 ví dụ khác :
SELECT userId, userName, userPhone
FROM User
WHERE dept = 'ruby' or rank = '5' or division = '2'
SELECT userId, userName, userPhone FROM User
WHERE dept = 'ruby' UNION ALL
SELECT userId, userName, userPhone FROM User
WHERE rank = '5' UNION ALL
SELECT userId, userName, userPhone FROM User
WHERE division = '2'
- DISTINCT, ORDER BY Đừng sử dụng DISTINCT và ORDER BY trong câu lệnh SELECT trừ khi thật sự cần thiết, DISTINCT sẽ kiểm tra và loại bỏ các bản ghi trùng lặp ORDER BY sẽ sort các records hầu hết các trường hợp 2 thao tác này chiếm phần lớn thời gian truy vấn.
- COUNT() vs IF EXISTS Khi xác định sự tồn tại của records trong bảng nên dùng IF EXISTS thay cho COUNT() hoặc COUNT(DISTINCT).
IF (SELECT COUNT(*) FROM table_name WHERE column_name = 'xxx')
Hàm COUNT sẽ tìm cách lấy tất cả phần tử, so sánh, đếm nên sẽ tốn tài nguyên và nhiều thao tác hơn.Hãy dùng
IF EXISTS (SELECT * FROM table_name WHERE column_name = 'xxx')
Sử dụng SQL Procedue
- Đối với các thao tác được thực hiện 1 cách thường xuyên và có xử lý phức tạp ta sử dụng SQL procedure(SP) với nhiều lợi ích như dưới đây.
- Giảm lượng dữ liệu truyền đến Server SP được lưu sẵn ở phía server do đó không cần phải gửi cả câu lệnh SQL dài tới server mà chỉ cần gửi tham số.
- SP được biên dịch ngay ở lần đầu chạy, những lần sau chạy SP sẽ sử dụng lại file đã biên dịch trước đó nên tốc độ sẽ nhanh hơn.
- Mặt khác khi sử dụng SP trong source có thể dùng vòng for để gọi nhiều câu lệnh SQL gửi lên server điều này giúp tái sử dụng source.
Kết luận và chú ý
- đối với developer việc tinh chỉnh lại câu sql không tốn nhiều công sức nhưng sẽ giúp hệ thống giảm thiểu tính toán đáng kể.
- một số mục tối ưu ở trên mặc dù sử dụng được index giúp truy vấn nhanh hơn nhưng ngược lại làm chậm thao tác INSERT ,UPDATE do đó hãy cân nhắc toàn bộ hệ thống trước khi áp dụng.
- Có rất nhiều lý do để tập luyện cho mình quen với lối viết SQL tối ưu. Khi bạn áp dụng thành thạo những thủ thuật nhỏ nêu trên và biến nó thành thói quen mỗi khi viết câu lệnh.Những thủ thuật rất đơn giản này còn giúp bạn tận dụng tốt hơn tài nguyên máy chủ trong quá trình xử lý câu lệnh.
Chúng tôi chuyên cung cấp những khóa học về tối ưu câu lệnh (SQL level 2), Xây dựng kho dữ liệu (Data Warehouse), Phân tích dữ liệu,… đăng ký ngay để nhận được tư vấn chi tiết lộ trình dành riêng cho bạn nhé!
Ngoài ra, Chúng tôi chuyên cung cấp các dịch vụ về Xây dựng Kho dữ liệu Data Warehouse/ Xây dựng Báo cáo Power BI cho các doanh nghiệp lớn như: Nakagawa, Mutosi, Tinh Vân Group,….. đăng ký ngay để được Demo và tư vấn miễn phí dành riêng cho doanh nghiệp của bạn.

