Table of Contents
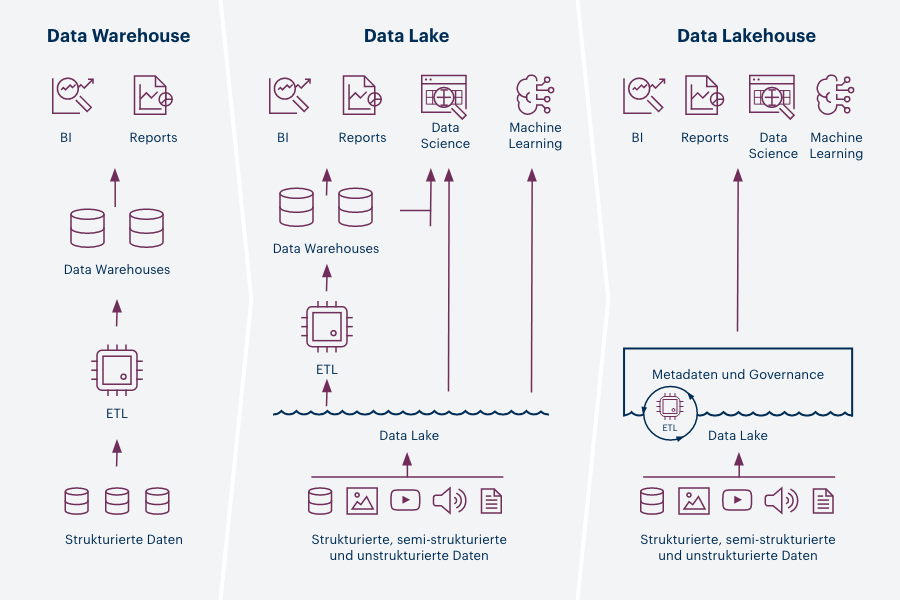
Data Warehouse Architecture là gì ?
Data Warehouse Architecture là một phương pháp xác định kiến trúc tổng thể của quá trình xử lý và trình bày giao tiếp dữ liệu tồn tại cho máy tính của khách hàng cuối trong doanh nghiệp. Mỗi kho dữ liệu đều khác nhau, nhưng tất cả đều được đặc trưng bởi các thành phần quan trọng tiêu chuẩn.
Các ứng dụng sản xuất như tài khoản trả lương phải trả khi mua sản phẩm và kiểm soát hàng tồn kho được thiết kế để xử lý giao dịch trực tuyến (OLTP). Các ứng dụng như vậy thu thập dữ liệu chi tiết từ các hoạt động hàng ngày.
Các ứng dụng Data Warehouse được thiết kế để hỗ trợ các yêu cầu dữ liệu đặc biệt của người dùng, một hoạt động gần đây được gọi là xử lý phân tích trực tuyến (OLAP). Chúng bao gồm các ứng dụng như dự báo, lập hồ sơ, báo cáo tóm tắt và phân tích xu hướng.
Cơ sở dữ liệu sản xuất được cập nhật liên tục bằng tay hoặc thông qua các ứng dụng OLTP. Ngược lại, cơ sở dữ liệu kho hàng được cập nhật định kỳ từ các hệ thống vận hành, thường là trong giờ ngoài giờ. Khi dữ liệu OLTP được tích lũy trong cơ sở dữ liệu sản xuất, nó thường xuyên được trích xuất, lọc và sau đó được tải vào một máy chủ kho chuyên dụng mà người dùng có thể truy cập. Khi kho được nhập, nó phải được cấu trúc lại các bảng không chuẩn hóa, dữ liệu được làm sạch các lỗi và phần dư thừa, các trường và khóa mới được thêm vào để phản ánh nhu cầu sắp xếp, kết hợp và tổng hợp dữ liệu của người dùng.
Kho dữ liệu và kiến trúc của chúng phụ thuộc rất nhiều vào các yếu tố tình huống của tổ chức.
Ba kiến trúc phổ biến là:
- Data Warehouse Architecture: Basic
- Data Warehouse Architecture: With Staging Area
- Data Warehouse Architecture: With Staging Area and Data Marts
Three-Tier Data Warehouse Architecture (Kho dữ liệu có kiến trúc ba cấp)
Kho dữ liệu thường có kiến trúc ba cấp (bậc) bao gồm:
- Bottom Tier (Data Warehouse Server)
- Middle Tier (OLAP Server)
- Top Tier (Front end Tools).
Tầng dưới cùng bao gồm máy chủ Data Warehouse, hầu như luôn luôn là RDBMS. Nó có thể bao gồm một số kho dữ liệu chuyên biệt và một kho lưu trữ siêu dữ liệu.
Dữ liệu từ cơ sở dữ liệu hoạt động và các nguồn bên ngoài (chẳng hạn như dữ liệu hồ sơ người dùng do tư vấn bên ngoài cung cấp) được trích xuất bằng giao diện chương trình ứng dụng được gọi là cổng. Một cổng được cung cấp bởi DBMS bên dưới và cho phép các chương trình của khách hàng tạo mã SQL để được thực thi tại một máy chủ.
Ví dụ về các cổng chứa ODBC (Kết nối cơ sở dữ liệu mở) và OLE-DB (Liên kết mở và nhúng cho cơ sở dữ liệu) của Microsoft và JDBC (Kết nối cơ sở dữ liệu Java).
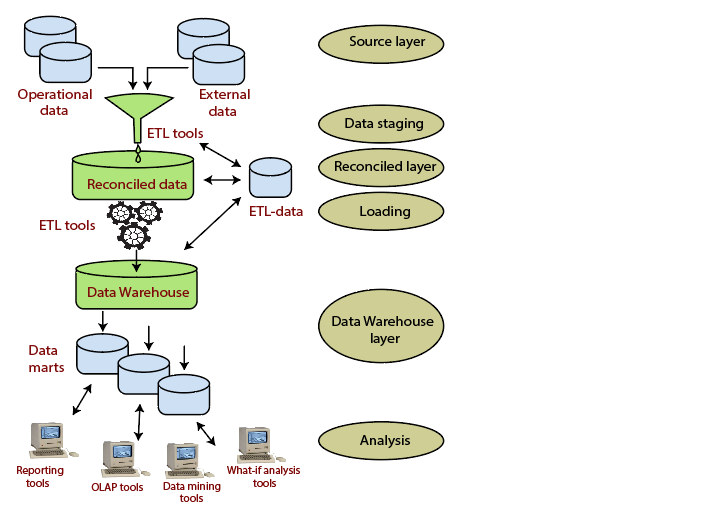
Tầng giữa bao gồm một máy chủ OLAP để truy vấn nhanh kho dữ liệu.
Máy chủ OLAP được triển khai bằng cách sử dụng
(1) Relational OLAP (ROLAP) model, tức là một DBMS quan hệ mở rộng ánh xạ các chức năng trên dữ liệu đa chiều với các phép toán quan hệ chuẩn.
(2) Multidimensional OLAP (MOLAP) model, tức là một máy chủ mục đích cụ thể trực tiếp triển khai các hoạt động và thông tin đa chiều.
Tầng cao nhất chứa các công cụ giao diện người dùng để hiển thị kết quả do OLAP cung cấp, cũng như các công cụ bổ sung để khai thác dữ liệu đối với dữ liệu do OLAP tạo ra.
Kiến trúc Kho dữ liệu tổng thể được hiển thị trong hình:

Kho siêu dữ liệu lưu trữ thông tin xác định các đối tượng DW. Nó bao gồm các thông số và thông tin sau cho các ứng dụng cấp trung bình và cấp cao nhất:
- Mô tả cấu trúc DW, bao gồm lược đồ kho, kích thước, cấu trúc phân cấp, vị trí trung tâm dữ liệu và nội dung, v.v.
- Siêu dữ liệu hoạt động, thường mô tả mức đơn vị tiền tệ của dữ liệu được lưu trữ, tức là thông tin đang hoạt động, được lưu trữ hoặc đã được xóa và giám sát kho, tức là thống kê sử dụng, báo cáo lỗi, kiểm tra, v.v.
- Dữ liệu hiệu suất hệ thống, bao gồm các chỉ số, được sử dụng để cải thiện hiệu suất truy xuất và truy xuất dữ liệu.
- Thông tin về ánh xạ từ cơ sở dữ liệu hoạt động, cung cấp các RDBMS nguồn và nội dung của chúng, các quy tắc làm sạch và chuyển đổi, v.v.
- Thuật toán tóm tắt, truy vấn xác định trước và báo cáo dữ liệu kinh doanh, bao gồm các thuật ngữ và định nghĩa kinh doanh, thông tin quyền sở hữu, v.v.
Nguyên tắc lưu trữ dữ liệu

Load Performance
Kho dữ liệu yêu cầu tăng tải dữ liệu mới theo định kỳ trong khoảng thời gian hẹp; hiệu suất trong quá trình tải phải được đo bằng hàng trăm triệu hàng và gigabyte mỗi giờ và không được hạn chế khối lượng kinh doanh dữ liệu một cách giả tạo.
Load Processing
Nhiều giai đoạn phải được thực hiện để tải mới hoặc cập nhật dữ liệu vào kho dữ liệu, bao gồm chuyển đổi dữ liệu, lọc, định dạng lại, lập chỉ mục và cập nhật siêu dữ liệu.
Data Quality Management
Quản lý dựa trên thực tế đòi hỏi chất lượng dữ liệu cao nhất. Kho đảm bảo tính nhất quán cục bộ, tính nhất quán toàn cầu và tính toàn vẹn tham chiếu bất chấp các nguồn “bẩn” và kích thước cơ sở dữ liệu lớn.
Query Performance
Quản lý dựa trên thực tế không được làm chậm hiệu suất của RDBMS kho dữ liệu; các truy vấn lớn, phức tạp phải được hoàn thành trong vài giây, không phải vài ngày.
Terabyte Scalability
Quy mô kho dữ liệu đang tăng lên với tốc độ đáng kinh ngạc. Ngày nay, các kho dữ liệu này có kích thước từ vài đến hàng trăm gigabyte và kích thước hàng terabyte.
Nguồn: Internet
Chúng tôi chuyên cung cấp các dịch vụ về Xây dựng Kho dữ liệu Data Warehouse/ Xây dựng Báo cáo Power BI cho các doanh nghiệp lớn như: Nakagawa, Mutoshi, Tinh Vân Group,….. đăng ký ngay để được Demo và tư vấn miễn phí dành riêng cho doanh nghiệp của bạn.