Table of Contents
Data Warehouse là gì?
Data Warehouse có nghĩa là kho dữ liệu là một loại quản lý dữ liệu hệ thống được thiết kế để cho phép và hỗ trợ kinh doanh thông minh hoạt động BI, đặc biệt là phân tích. Data Warehouse chỉ nhằm mục đích thực hiện các truy vấn và phân tích và thường chứa một lượng lớn dữ liệu. Dữ liệu trong Data Warehouse thường được lấy từ nhiều nguồn như tệp nhật ký ứng dụng và ứng dụng giao dịch.
Data Warehouse tập trung và tổng hợp một lượng lớn dữ liệu từ nhiều nguồn. Khả năng phân tích Data Warehouse cho phép các tổ chức thu được những hiểu biết kinh doanh có giá trị từ dữ liệu của họ để cải thiện việc ra quyết định. Theo thời gian, nó xây dựng một hồ sơ lịch sử có thể là vô giá đối với các nhà Data Science và nhà phân tích kinh doanh.
Một Data Warehouse điển hình thường bao gồm các yếu tố sau:
- Một cơ sở dữ liệu quan hệ để lưu trữ và quản lý dữ liệu.
- Giải pháp trích xuất, tải và biến đổi ELT để chuẩn bị dữ liệu cho phân tích.
- Khả năng phân tích thống kê, báo cáo và khai thác dữ liệu.
- Các công cụ phân tích khách hàng để trực quan hóa và trình bày dữ liệu cho người dùng doanh nghiệp.
- Các ứng dụng phân tích khác, phức tạp hơn tạo ra thông tin có thể hành động bằng cách áp dụng khoa học dữ liệu và thuật toán trí tuệ nhân tạo AI hoặc các tính năng đồ thị và không gian cho phép nhiều loại phân tích dữ liệu hơn trên quy mô lớn
Các loại Data Warehouses

Host-Based Data Warehouses
Có hai loại Data Warehouses dựa trên máy chủ có thể được triển khai:
Các kho máy tính lớn dựa trên máy chủ lưu trữ trên cơ sở dữ liệu khối lượng lớn. Được hỗ trợ bởi cấu trúc dung lượng cao mạnh mẽ và đáng tin cậy như hệ thống IBM / 390, UNISYS và hệ thống tuần tự Dữ liệu Chung, và các cơ sở dữ liệu như Sybase, Oracle, Informix và DB2.
Các Data Warehouses LAN dựa trên máy chủ, nơi việc phân phối dữ liệu có thể được xử lý tập trung hoặc từ môi trường nhóm làm việc. Kích thước của các Data Warehouses của cơ sở dữ liệu phụ thuộc vào nền tảng.
Các công cụ trích xuất và chuyển đổi dữ liệu cho phép trích xuất và làm sạch tự động dữ liệu từ các hệ thống sản xuất. Không thể áp dụng cho phép truy cập trực tiếp bằng công cụ truy vấn vào các loại phương pháp này vì những lý do sau:
Một khối lượng lớn các truy vấn kho bãi phức tạp có thể có quá nhiều tác động có hại đối với ứng dụng định hướng xử lý giao dịch quan trọng (TP).
Các hệ thống TP này đã và đang phát triển trong thiết kế cơ sở dữ liệu của chúng cho thông lượng giao dịch. Trong tất cả các phương pháp, cơ sở dữ liệu được thiết kế để xử lý truy vấn hoặc giao dịch tối ưu. Một truy vấn nghiệp vụ phức tạp cần sự kết hợp của nhiều bảng chuẩn hóa và kết quả là hiệu suất thường sẽ kém và cấu trúc truy vấn phần lớn phức tạp.
Không có gì đảm bảo rằng dữ liệu trong hai hoặc nhiều phương pháp sản xuất sẽ nhất quán.
Host-Based (MVS) Data Warehouses
Các Data Warehouses sử dụng nằm trên cơ sở dữ liệu khối lượng lớn trên MVS là loại Data Warehouses dựa trên máy chủ lưu trữ. Thường thì DBMS là DB2 với rất nhiều nguồn gốc cho thông tin kế thừa, bao gồm VSAM, DB2, tệp phẳng và Hệ thống quản lý thông tin (IMS).

Trước khi bắt tay vào thiết kế, xây dựng và triển khai một nhà kho như vậy, cần phải cân nhắc thêm một số điều vì
- Các cơ sở dữ liệu như vậy thường có khối lượng lưu trữ dữ liệu rất cao.
- Các kho như vậy có thể yêu cầu hỗ trợ cho cả MVS và các phương tiện truy vấn và báo cáo dựa trên khách hàng.
- Các kho này có hệ thống nguồn phức tạp.
- Các hệ thống như vậy cần được bảo trì liên tục vì chúng cũng phải được sử dụng cho các mục tiêu quan trọng.
Để làm cho việc xây dựng các Data Warehouses như vậy thành công, thường tuân theo các giai đoạn sau:
- Unload Phase: Nó chứa lựa chọn và lọc dữ liệu hoạt động.
- Transform Phase: Để dịch nó thành một dạng thích hợp và mô tả các quy tắc để truy cập và lưu trữ nó.
- Load Phase: Để di chuyển bản ghi trực tiếp vào các bảng DB2 hoặc một tệp cụ thể để chuyển nó vào cơ sở dữ liệu khác hoặc kho không phải MVS.
Một kho lưu trữ Siêu dữ liệu tích hợp là trung tâm của bất kỳ môi trường Data Warehouses nào. Cần có một cơ sở như vậy để ghi lại các nguồn dữ liệu, các quy tắc dịch dữ liệu và các khu vực người dùng vào kho. Nó cung cấp một mạng động giữa nhiều cơ sở dữ liệu nguồn dữ liệu và DB2 của các Data Warehouses có điều kiện.
Kho lưu trữ siêu dữ liệu là cần thiết để thiết kế, xây dựng và duy trì các quy trình Data Warehouses. Nó phải có khả năng cung cấp dữ liệu về dữ liệu nào tồn tại trong cả hệ thống hoạt động và Data Warehouses, nơi dữ liệu được đặt. Ánh xạ dữ liệu hoạt động đến các trường kho và các kỹ thuật truy cập người dùng cuối. Truy vấn, báo cáo và bảo trì là một phương pháp không thể thiếu khác của Data Warehouses như vậy. Một công cụ báo cáo và truy vấn dựa trên MVS dành cho DB2.
Host-Based (UNIX) Data Warehouses
Oracle và Informix RDBMS hỗ trợ cơ sở vật chất cho các Data Warehouses như vậy. Cả hai cơ sở dữ liệu này đều có thể trích xuất thông tin từ cơ sở dữ liệu dựa trên MVS¬ cũng như một số lượng lớn hơn các cơ sở dữ liệu dựa trên UNIX¬ khác. Các loại kho này tuân theo giai đoạn tương tự như các Data Warehouses MVS dựa trên máy chủ. Ngoài ra, có thể tạo dữ liệu từ các máy chủ mạng khác nhau. Vì tính nhất quán của thuộc tính tệp là thường xuyên trên toàn mạng.
LAN-Based Workgroup Data Warehouses
Kho nhóm làm việc dựa trên mạng LAN là một cấu trúc tích hợp để xây dựng và duy trì một Data Warehouses trong môi trường mạng LAN. Trong kho này, chúng ta có thể trích xuất thông tin từ nhiều nguồn khác nhau và hỗ trợ nhiều kho dựa trên mạng LAN, cơ sở dữ liệu kho thường được chọn để bao gồm họ DB2, Oracle, Sybase và Informix. Các cơ sở dữ liệu khác cũng có thể được chứa thông qua không thường xuyên là IMS, VSAM, Flat File, MVS và VH.

Được thiết kế cho môi trường nhóm làm việc, kho nhóm làm việc dựa trên mạng LAN là tối ưu cho bất kỳ tổ chức kinh doanh nào muốn xây dựng một Data Warehouses thường được gọi là data mart. Loại Data Warehouses này thường yêu cầu đầu tư ban đầu tối thiểu và đào tạo kỹ thuật.
Data Delivery: Với kho nhóm làm việc dựa trên mạng LAN, khách hàng cần có kiến thức kỹ thuật tối thiểu để tạo và duy trì một Data Warehouses được tùy chỉnh để sử dụng ở cấp bộ phận, đơn vị kinh doanh hoặc nhóm làm việc. Kho nhóm làm việc dựa trên mạng LAN đảm bảo việc cung cấp thông tin từ công ty
đánh giá cao tài nguyên bằng cách cung cấp quyền truy cập vận tải vào dữ liệu trong kho.
Host-Based Single Stage (LAN) Data Warehouses
Trong Data Warehouses dựa trên mạng LAN, việc phân phối dữ liệu có thể được xử lý tập trung hoặc từ môi trường nhóm làm việc để các nhóm kinh doanh có thể đáp ứng quy trình xử lý dữ liệu cần thiết của họ mà không tạo gánh nặng cho tài nguyên CNTT tập trung, tận hưởng quyền tự chủ của Data Warehouses của họ mà không bao gồm tính toàn vẹn và bảo mật dữ liệu tổng thể trong xí nghiệp.

Hạn chế
Cả hai phương pháp DBMS và khả năng mở rộng phần cứng thường hạn chế các giải pháp lưu trữ dựa trên mạng LAN.
Nhiều doanh nghiệp dựa trên mạng LAN đã không thực hiện đầy đủ các phương pháp lập lịch công việc, quản lý khôi phục, bảo trì có tổ chức và giám sát hiệu suất để cung cấp các giải pháp kho bãi hiệu quả.
Thường thì các kho này phụ thuộc vào các nền tảng khác để ghi nguồn. Việc xây dựng một môi trường có tính toàn vẹn, khả năng phục hồi và bảo mật của dữ liệu đòi hỏi phải thiết kế, lập kế hoạch và triển khai cẩn thận. Nếu không, việc đồng bộ hóa quá trình chuyển đổi và tải từ các nguồn đến máy chủ có thể gây ra vô số vấn đề.
Một kho dựa trên mạng LAN cung cấp dữ liệu từ nhiều nguồn yêu cầu đầu tư ban đầu tối thiểu và kiến thức kỹ thuật. Kho dựa trên mạng LAN cũng có thể làm việc với các công cụ sao chép để tạo và cập nhật Data Warehouses. Loại kho này có thể bao gồm chế độ xem doanh nghiệp, lịch sử, tổng hợp, các phiên bản trong và hỗ trợ nguồn không đồng nhất, chẳng hạn như
- DB2 Family
- IMS, VSAM, Flat File [MVS and VM]
Một cửa hàng duy nhất thường điều khiển một kho dựa trên mạng LAN và cung cấp các ứng dụng DSS hiện có, cho phép người dùng doanh nghiệp định vị dữ liệu trong Data Warehouses của họ. Kho dựa trên mạng LAN có thể hỗ trợ người dùng doanh nghiệp với giải pháp thông tin dữ liệu hoàn chỉnh. Kho dựa trên mạng LAN cũng có thể chia sẻ siêu dữ liệu với khả năng phân loại dữ liệu kinh doanh và làm cho nó khả thi cho bất kỳ ai cần.
Multi-Stage Data Warehouses
Nó đề cập đến nhiều giai đoạn trong việc chuyển đổi phương pháp để phân tích dữ liệu thông qua tổng hợp. Nói cách khác, phân đoạn dữ liệu nhiều lần trước khi thực hiện thao tác tải vào Data Warehouses, dữ liệu sẽ được hệ thống nguồn biểu mẫu trích xuất đến khu vực dàn dựng trước, sau đó được tải vào Data Warehouses sau khi thay đổi và cuối cùng đến các Data Warehouses theo bộ phận.
Cấu hình này rất phù hợp với các môi trường mà khách hàng cuối với nhiều khả năng yêu cầu quyền truy cập vào cả thông tin tóm tắt cho các quyết định chiến thuật đến từng phút cũng như tóm tắt, một hồ sơ giao hoán cho các quyết định chiến lược dài hạn. Cả Data Warehouses hoạt động (ODS) và Data Warehouses có thể nằm trên cơ sở dữ liệu dựa trên máy chủ hoặc dựa trên mạng LAN, tùy thuộc vào khối lượng và yêu cầu tùy chỉnh. Chúng chứa DB2, Oracle, Informix, IMS, Flat Files và Sybase.
Thông thường, ODS chỉ lưu trữ các bản ghi cập nhật nhất. Data Warehouses lưu trữ quá trình tính toán lịch sử của các tệp. Lúc đầu, thông tin trong cả hai cơ sở dữ liệu sẽ rất giống nhau. Ví dụ, các bản ghi cho một khách hàng mới sẽ trông giống nhau. Khi các thay đổi đối với bản ghi người dùng xảy ra, OD sẽ được làm mới để chỉ phản ánh dữ liệu mới nhất, trong khi Data Warehouses sẽ chứa cả dữ liệu lịch sử và thông tin mới. Do đó, yêu cầu về khối lượng của Data Warehouses sẽ vượt quá yêu cầu về khối lượng của ODS ngoài giờ. Việc đạt được tỷ lệ 4 trên 1 trong thực tế là điều không quen thuộc.

Stationary Data Warehouses
Trong loại Data Warehouses này, dữ liệu không bị thay đổi từ các nguồn, như thể hiện trong hình:
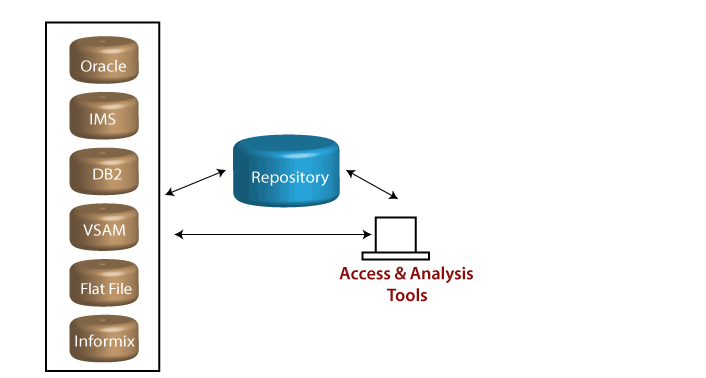
Thay vào đó, khách hàng được cấp quyền truy cập trực tiếp vào dữ liệu. Đối với nhiều tổ chức, việc truy cập không thường xuyên, các vấn đề về khối lượng hoặc các nhu cầu thiết yếu của công ty quyết định như cách tiếp cận. Lược đồ này tạo ra một số vấn đề cho khách hàng, chẳng hạn như
- Xác định vị trí của thông tin cho người dùng
- Cung cấp cho khách hàng khả năng truy vấn các DBMS khác nhau vì chúng đều là một DBMS duy nhất với một API duy nhất.
- Tác động đến hiệu suất vì khách hàng sẽ cạnh tranh với các cửa hàng dữ liệu sản xuất.
Một nhà kho như vậy sẽ cần ‘phần mềm trung gian’ chuyên biệt cao và tinh vi có thể chỉ với một tương tác duy nhất với khách hàng. Điều này cũng có thể cần thiết cho một cơ sở để hiển thị bản ghi đã trích xuất cho người dùng trước khi tạo báo cáo. Một kho lưu trữ siêu dữ liệu tích hợp trở thành một điều cần thiết tuyệt đối trong môi trường này.
Distributed Data Warehouses
Khái niệm Data Warehouses phân tán gợi ý rằng có hai loại Data Warehouses phân tán và các sửa đổi của chúng cho các kho doanh nghiệp cục bộ được phân phối trong toàn doanh nghiệp và kho toàn cầu như được thể hiện trong hình:
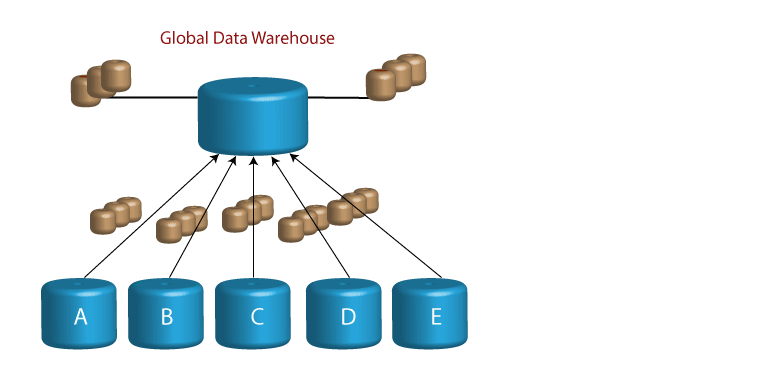
Đặc điểm của Data Warehouses cục bộ
- Hoạt động xuất hiện ở cấp cục bộ
- Hàng loạt quy trình vận hành
- Trang web địa phương là tự trị
- Mỗi Data Warehouses cục bộ có kiến trúc và nội dung dữ liệu độc đáo
- Dữ liệu là duy nhất và quan trọng hàng đầu chỉ đối với địa phương đó
- Phần lớn hồ sơ là địa phương và không tái
- chuyên tâm
- Bất kỳ sự giao nhau nào của dữ liệu giữa các Data Warehouses cục bộ là không thể tránh khỏi
- Kho địa phương phục vụ các cộng đồng kỹ thuật khác nhau
- Phạm vi của các Data Warehouses cục bộ là hữu hạn đối với trang cục bộ
- Kho địa phương cũng bao gồm dữ liệu lịch sử và chỉ được tích hợp trong trang web địa phương.
Virtual Data Warehouses
Data Warehouses ảo được tạo theo các giai đoạn sau:
- Cài đặt một bộ phương pháp tiếp cận dữ liệu, từ điển dữ liệu và các phương tiện quản lý quy trình.
- Đào tạo khách hàng cuối.
- Giám sát cách các cơ sở DW sẽ được sử dụng
- Dựa trên mức sử dụng thực tế, Data Warehouses vật lý được tạo ra để cung cấp kết quả tần số cao
Chiến lược này xác định rằng người dùng cuối được phép truy cập trực tiếp vào cơ sở dữ liệu hoạt động bằng cách sử dụng bất kỳ công cụ nào được triển khai cho mạng truy cập dữ liệu. Phương pháp này cung cấp tính linh hoạt tối ưu cũng như lượng thông tin dư thừa tối thiểu phải được tải và duy trì. Data Warehouses là một ý tưởng tuyệt vời, nhưng rất khó để xây dựng và cần đầu tư. Tại sao không sử dụng một phương pháp rẻ và nhanh chóng bằng cách loại bỏ giai đoạn chuyển đổi kho lưu trữ cho siêu dữ liệu và cơ sở dữ liệu khác. Phương pháp này được gọi là ‘Data Warehouses ảo’.
Để thực hiện điều này, cần phải xác định bốn loại dữ liệu:
- Một từ điển dữ liệu bao gồm các định nghĩa của các cơ sở dữ liệu khác nhau.
- Mô tả mối quan hệ giữa các thành phần dữ liệu.
- Mô tả của phương pháp người dùng sẽ giao diện với hệ thống.
- Các thuật toán và quy tắc kinh doanh mô tả những việc cần làm và cách thực hiện.
Nhược điểm
Vì các truy vấn cạnh tranh với các giao dịch hồ sơ sản xuất, hiệu suất có thể bị giảm sút.
Không có siêu dữ liệu, không có bản ghi tóm tắt hoặc không có lịch sử hoặc tích hợp DSS (Hệ thống hỗ trợ quyết định) riêng lẻ. Tất cả các truy vấn phải được sao chép, gây thêm gánh nặng cho hệ thống.
Không có quá trình làm mới, khiến các truy vấn rất phức tạp.

Nguồn: Internet
Chúng tôi chuyên cung cấp các dịch vụ về Xây dựng Kho dữ liệu Data Warehouse/ Xây dựng Báo cáo Power BI cho các doanh nghiệp lớn như: Nakagawa, Mutoshi, Tinh Vân Group,….. đăng ký ngay để được Demo và tư vấn miễn phí dành riêng cho doanh nghiệp của bạn.